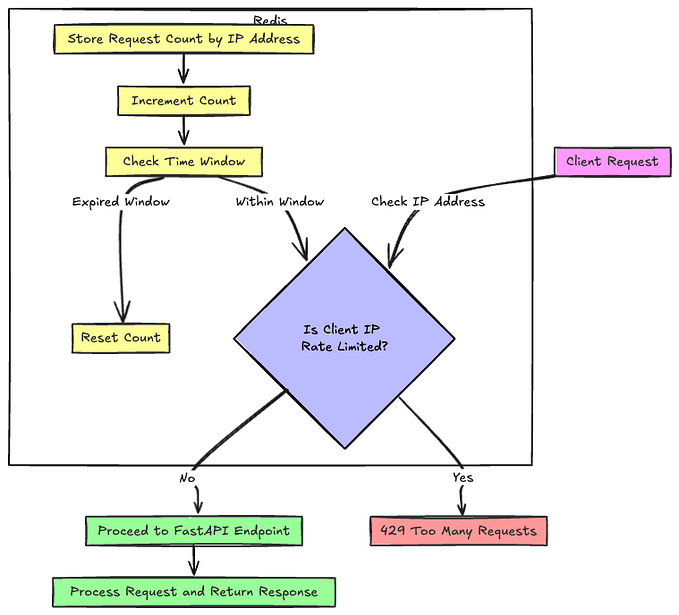
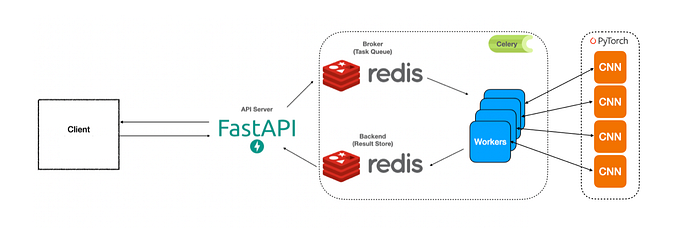
Building a GPT Pipeline: From Data to Deployment
The rise of Generative Pretrained Transformers (GPT) has revolutionized the world of NLP by enabling advanced language generation tasks. In this blog, we’ll explore the key steps to build and deploy a GPT pipeline, from training data preparation to model deployment. Whether you’re a beginner or an advanced developer, this guide will walk you through every phase of the process.
Table of Contents
- Introduction to GPT and Transformer Models
- Building Blocks of a GPT Pipeline
- Step-by-Step Guide to Implementing a GPT Pipeline
- Data Collection and Preprocessing
- Model Training
- Fine-tuning the GPT Model
- Testing and Evaluation
- Deploying the GPT Pipeline in Production
- Challenges and Best Practices
- Conclusion
1. Introduction to GPT and Transformer Models
GPT (Generative Pretrained Transformer) is a class of autoregressive language models that use deep learning to generate human-like text. These models are based on the Transformer architecture, which has become the backbone of modern NLP.
Key Concepts:
- Transformer architecture: Introduced in the paper “Attention Is All You Need” by Vaswani et al., the transformer model uses attention mechanisms to process input data.
- Pretraining and fine-tuning: GPT models are first pretrained on large datasets and then fine-tuned on task-specific data.
- GPT applications: Chatbots, content generation, code completion, language translation, etc.
2. Building Blocks of a GPT Pipeline
Building a GPT pipeline involves multiple components that work together to enable the model to generate text. Below are the core building blocks:
- Data Collection & Preprocessing:
- Collect or create a large dataset.
- Preprocess the data to ensure consistency (e.g., tokenization).
- Model Training:
- Train a GPT model on your dataset or fine-tune an existing pre-trained model (like OpenAI’s GPT-3 or GPT-4).
- Model Fine-Tuning:
- Customize the model for specific tasks, such as summarization, chat, etc.
- Evaluation and Testing:
- Evaluate model performance using metrics like perplexity, BLEU score, or human evaluation.
- Model Deployment:
- Deploy your model using tools like Docker, Kubernetes, or cloud platforms (e.g., AWS, GCP).
- Monitoring and Maintenance:
- Monitor the model in production for drift, performance, and necessary updates.
3. Step-by-Step Guide to Implementing a GPT Pipeline
Step 1: Data Collection and Preprocessing
A GPT pipeline starts with data. High-quality, diverse, and large datasets are crucial for training powerful language models.
- Data Sources: Collect data from web scraping, public datasets, or proprietary sources.
- Preprocessing Techniques:
- Tokenization: Break text into smaller chunks (tokens).
- Lowercasing: Convert text to lowercase for uniformity.
- Removing Stop Words: Filter out words that don’t contribute to the meaning of a sentence (optional).
- Sentence Segmentation: Break text into sentences.
Example code for tokenization:
from transformers import GPT2Tokenizertokenizer = GPT2Tokenizer.from_pretrained("gpt2")
text = "This is a sample text for tokenization."
tokens = tokenizer.tokenize(text)Step 2: Model Training
Once your data is ready, the next step is to train your GPT model. You can either train from scratch (requiring massive computational resources) or fine-tune a pre-trained model.
- Pre-trained Models: Using models like GPT-2, GPT-3, or GPT-4.
- Training Environment: Set up a GPU-powered environment for efficient training. Platforms like Google Colab, AWS, and GCP provide access to GPUs.
Example fine-tuning with Hugging Face:
from transformers import GPT2LMHeadModel, GPT2Tokenizer, Trainer, TrainingArgumentsmodel = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")# Define your training arguments
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=1,
per_device_train_batch_size=2,
)# Define the Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset, # Assuming `train_dataset` is preprocessed
)# Start training
trainer.train()
Step 3: Fine-Tuning the GPT Model
Fine-tuning involves training your pre-trained GPT model on a task-specific dataset (e.g., a dataset for customer service responses or specific text domains like legal or medical data).
- Specialized Fine-Tuning: Modify the loss function and learning rate to focus on task-specific accuracy.
Example:
# Use custom datasets for fine-tuning
fine_tuned_model = model.train(train_dataset)Step 4: Testing and Evaluation
Once the model is fine-tuned, testing it on unseen data is essential. Use metrics like perplexity or human evaluation for text generation tasks.
- Evaluation Metrics:
- Perplexity: A measure of how well the model predicts a sample.
- BLEU: Measures the similarity between machine-generated text and reference text.
# Evaluate perplexity
def evaluate(model, test_dataset):
loss = model.evaluate(test_dataset)
perplexity = torch.exp(torch.tensor(loss))
return perplexity4. Deploying the GPT Pipeline in Production
Step 1: Containerization with Docker
Docker allows for easy packaging of your model and its dependencies. You can write a Dockerfile to create an image of your GPT pipeline.
FROM python:3.8-slimCOPY . /app
WORKDIR /appRUN pip install -r requirements.txt
CMD ["python", "app.py"]
Step 2: Using Cloud Platforms
Cloud platforms like AWS, Azure, and GCP offer services like API Gateway and Lambda for deploying GPT models as web services.
- AWS Lambda: Deploy your model as a serverless function for scalability.
- GCP AI Platform: Deploy your model for real-time predictions.
Step 3: Monitoring and Scaling
Once deployed, monitor your model using tools like Prometheus and Grafana to ensure it performs efficiently under different loads.
5. Challenges and Best Practices
Building a GPT pipeline involves challenges:
- Computational Costs: Training a GPT model requires significant computational resources.
- Bias in Data: GPT models can inherit biases from the training data, requiring careful dataset curation.
- Model Interpretability: Understanding why the model generates specific outputs is difficult.
Best Practices
- Start with Pre-trained Models: Fine-tuning pre-trained models is more practical than training from scratch.
- Optimize Hyperparameters: Experiment with different hyperparameters to find the best model performance.
- Monitor and Update: Regularly monitor your model in production and update it as new data becomes available.
6. Conclusion
Building and deploying a GPT pipeline is a complex but rewarding task. From data collection to model deployment, every step requires careful planning and execution. With the right tools and techniques, you can build scalable, high-performing GPT-powered applications that solve real-world problems.
Stay tuned for more tutorials on machine learning and NLP pipelines!
if you like it just hit the clap and comment :)